

OpenAI právě představilo GPT-5.2 Codex – nejpokročilejší AI model pro programování, který dokáže pracovat na složitých projektech celé hodiny bez dohledu. Tato technologie mění způsob, jakým firmy přistupují k vývoji softwaru a automatizaci kódu. Co to znamená pro běžné programátory, firmy a budoucnost softwarového inženýrství?
Co je GPT-5.2 Codex a proč je výjimečný?
Představte si kolegu programátora, který nikdy neusne, nezapomene na detaily a dokáže pracovat na vašem projektu i sedm hodin v kuse bez ztráty koncentrace. Právě takový je GPT-5.2 Codex – speciální verze modelu GPT-5.2, která byla vytrénována přímo na úkolech ze skutečného světa softwaru.
Na rozdíl od běžných AI asistentů, které vám jen radí nebo generují kousky kódu, GPT-5.2 Codex funguje jako plnohodnotný autonomní agent. Je to krok směrem k tomu, co odborníci z Apertia.ai nazývají „agentic AI“ – umělá inteligence, která nejen odpovídá na dotazy, ale aktivně řeší komplexní úkoly od začátku do konce.
Klíčové schopnosti GPT-5.2 Codex
Model dokáže autonomně zvládat celé spektrum vývojářských úkolů:
- Budování projektů od nuly – vytvoří kompletní aplikaci podle vaší specifikace
- Přidávání nových funkcí – rozšíří existující kód o požadované vlastnosti
- Inteligentní debugging – najde a opraví chyby samostatně, včetně testování
- Rozsáhlé refaktoring – přepíše a reorganizuje velké části kódu pro lepší strukturu
- Code review – zkontroluje kvalitu kódu a najde potenciální problémy ještě před nasazením
- Migrace mezi technologiemi – převede projekt z jednoho jazyka nebo frameworku do jiného
Porovnání s konkurencí: GPT-5.2 vs Claude Opus 4.5 vs Gemini 3 Pro
V listopadu a prosinci 2025 došlo k nebývalé konkurenční bitvě mezi třemi technologickými giganty. OpenAI, Anthropic (Claude) a Google (Gemini) vydali své nejpokročilejší modely během několika týdnů. Jak si GPT-5.2 Codex vede v přímém srovnání?
Tabulka porovnání klíčových benchmarků
| Benchmark | GPT-5.2 Codex | Claude Opus 4.5 | Gemini 3 Pro | Co měří |
|---|---|---|---|---|
| SWE-Bench Verified | 80.0% | 80.9% | 76.2% | Opravy reálných bugů z GitHubu |
| SWE-Bench Pro | 55.6% | – | – | Komplexní coding napříč jazyky |
| Terminal-Bench 2.0 | 47.6% | 59.3% | 54.2% | Práce v terminálu a CLI |
| GPQA Diamond | 92.4% | 87.0% | 91.9% | PhD-level vědecké otázky |
| ARC-AGI-2 | 52.9% | 37.6% | 31.1% | Abstraktní logické uvažování |
| AIME 2025 | 100% | 100% | 95% | Matematická soutěž |
| MMMU (Vision) | 84.2% | 77.8% | 83.0% | Multimodální porozumění |
| Cena vstup | $1.25/1M tokenů | $5/1M tokenů | ~$0.80/1M tokenů | Náklady na provoz |
| Cena výstup | $10/1M tokenů | $25/1M tokenů | ~$8/1M tokenů | Náklady na generování |
Praktické rozdíly z pohledu vývojářů
Podle nezávislých testů od vývojářských komunit:
- GPT-5.2 vytváří kód, který následuje běžné konvence a je snadno čitelný i pro juniory. Dobře se integruje do existujících workflow a spolehlivě dokončuje komplexní úkoly. Někdy může přidat extra validace nebo funkce, které jste nepožadovali.
- Claude Opus 4.5 generuje sofistikovanější řešení s lepší architektonickou separací. Je to jako senior architekt, který myslí dopředu. Někdy může být řešení zbytečně komplexní pro jednoduché úkoly. Výborný pro plánování velkých projektů.
- Gemini 3 Pro produkuje nejstručnější kód s důrazem na výkon. Skvělý pro prototypování a rychlé iterace. Někdy může vynechat edge cases nebo pokročilé funkce jako rate limiting. Ideální pro zkušené vývojáře, kteří ocení minimalistický přístup.
Jak si GPT-5.2 Codex vede v praxi?
Benchmark výsledky
Na benchmarku SWE-Bench Pro, který testuje schopnost řešit skutečné programátorské úkoly z produkčních repozitářů, dosáhl GPT-5.2 Codex úspěšnosti 55,6 %. To znamená, že dokáže vyřešit více než polovinu složitých úkolů napříč čtyřmi různými programovacími jazyky (Python, JavaScript, TypeScript a Go).
Pro srovnání – ještě před rokem byla úspěšnost top AI modelů na podobných benchmarcích kolem 20–30 %. GPT-5.2 Codex představuje téměř dvojnásobné zlepšení.
Adaptivní myšlení
Co je ještě důležitější než pouhá čísla – model dokáže pracovat efektivně a adaptivně. U jednoduchých požadavků reaguje rychle (používá o 93,7 % méně tokenů než GPT-5), zatímco u složitých refaktoringů a architektonických změn si vezme čas a pořádně si vše promyslí.
Během interního testování OpenAI zvládl GPT-5.2 Codex pracovat více než 7 hodin na jediném komplexním úkolu, přičemž sám testoval své řešení, opravoval chyby a iteroval nad implementací, dokud nedosáhl funkčního výsledku.
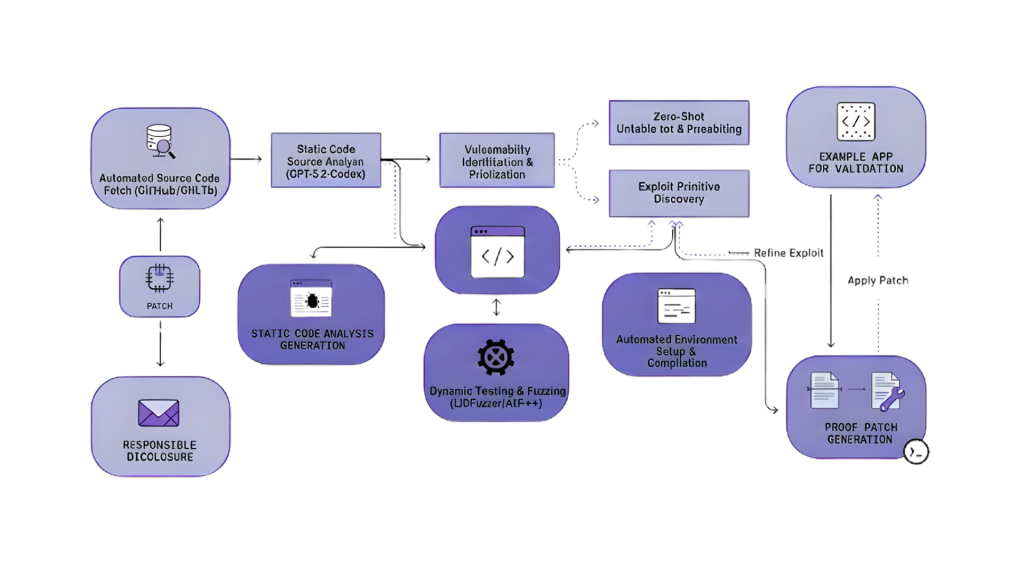
Tajná zbraň v kyberbezpečnosti
Jedním z nejzajímavějších a zároveň nejcitlivějších využití GPT-5.2 Codex je oblast kyberbezpečnosti. Moderní AI modely se stávají mocnými nástroji jak pro obranu, tak bohužel potenciálně i pro útok.
Reálný případ: Objevení zranitelnosti v React
Teprve 11. prosince 2025 bezpečnostní inženýr Andrew MacPherson ze společnosti Privy použil předchozí verzi modelu (GPT-5.1-Codex-Max) a objevil dosud neznámou zranitelnost v populární JavaScriptové knihovně React. Tato chyba mohla vést k úniku zdrojového kódu aplikací.
MacPherson zranitelnost odpovědně nahlásil a React tým ji okamžitě opravil. Tento incident ukázal, jak silným nástrojem se AI modely stávají pro bezpečnostní výzkum.
Vylepšené schopnosti detekce hrozeb
GPT-5.2 Codex je v oblasti kyberbezpečnosti ještě schopnější. Model dosahuje výrazně vyšší přesnosti v profesionálních Capture-the-Flag (CTF) soutěžích, které simulují skutečné kybernetické útoky a testují schopnost najít zranitelnosti.
Tato vylepšená výkonnost v CTF prostředích se přímo překládá do praxe:
- Rychlejší identifikace bezpečnostních chyb
- Lepší analýza hrozeb
- Automatizované testování penetrace
- Pomoc při bezpečnostním auditu kódu
Odpovědné nasazení
OpenAI si je dobře vědoma dual-use povahy tak silných nástrojů – mohou být použity jak pro dobro, tak pro zlo. Proto společnost zavádí několik ochranných opatření:
- Trusted Access Pilot Program – Jen prověření bezpečnostní odborníci s historií odpovědného zveřejňování zranitelností získají přístup k nejschopnějším verzím modelu pro obranné využití.
- Pokročilé monitorování – OpenAI implementovala dedikované monitorovací systémy specificky pro kybernetickou bezpečnost, které detekují a blokují podezřelé aktivity. Společnost už úspěšně zablokovala několik pokusů o zneužití modelů pro kybernetické operace.
- Postupné nasazení – Model je vydáván postupně s průběžným učením se z reálného použití a vylepšováním ochranných opatření.


